Стемминг и подсчёт слов с одинаковой основой в тексте на PHP
Стеммер Портера часто используется копирайтерами, сеошниками, др. в программных решениях для поиска и аналитики текстов, т. к. прост и не требует больших ресурсов. Из этой статьи вы узнаете, что такое стемминг и Стеммер Портера, сможете бесплатно скачать его PHP реализацию для русского и английского языков и приобрести полезный скрипт аналитики текстов «Stemmer».
Что такое Стемминг?Стемминг (от англ. stem — основа) — процесс нахождения основы слова для заданного исходного слова.
Алгоритм стемминга — вариант решения задачи нахождения основы слова, которая является давней проблемой в области компьютерных наук. Первый опубликованный стеммер был написан Джулии Бет Ловинс ещё в 1968 году.
В предлагаемом решении используется Стеммер Портера — алгоритм стемминга, опубликованный Мартином Портером в 1980 году, который не использует баз основ слова, а последовательно применяет к исходному слову ряд правил для отсечения окончаний и суффиксов слов, основываясь на особенностях того или иного языка.
Бесплатно скачать PHP-скрипт «Стеммер Портера» можно по ссылкам:
Примечание: следует учесть, что для русского языка используется кодировка UTF-8 и функции для работы с многобайтными строками. В частности, будет не лишним указать:
header('Content-Type: text/html; charset=UTF-8');
mb_internal_encoding('UTF-8');
Использовать «Стеммер Портера» можно подключив php-скрипт, создав объект и вызвав его функции getWordBase($word), где $word — переменная, значением которой является исходное слово, для которого нужно найти основу слова, например:
$word = 'стемминга';
include_once('stemmer_ru.php'); // подключение PHP-скрипта
$ru = new Stemmer_RU; // создание объекта
$stem = $ru->getWordBase($word); // получение основы слова
echo $stem; // выведет — стемминг
Для мульти-язычного текста советую добавить проверку входящих в слово знаков, например:
$word = 'стемминга';
include_once('stemmer_ru.php');
include_once('stemmer_en.php');
$ru = new Stemmer_RU;
$en = new Stemmer_EN;
if( preg_match("'^[а-я]+$'iu", $word) ){
$stem = $ru->getWordBase($word);
} elseif( preg_match("'^[a-z]+$'iu", $word) ){
$stem = $en->getWordBase($word);
}
Для получения слов из текста я использую следующий код:
$words = preg_match_all("'\w{2,}'u", $in, $m) ? $m[0] : array();
В данном случае спецсимвол \w представляет собой любую цифру, буку или знак подчеркивания, а значение {2,} определяет количество вхождений от 0 и более. Подробней о регулярных выражениях читайте «Шпаргалка: регулярные выражения в PHP»
Стемминг и подсчёт слов с одинаковой основой в тексте
Предлагаемое решение может быть полезно копирайтерам, сеошникам, др., т. к. позволяет проанализировать тексты конкурентов на предмет количества вхождений в них ключевых слов (их вариаций) и создать более релевантный контент.
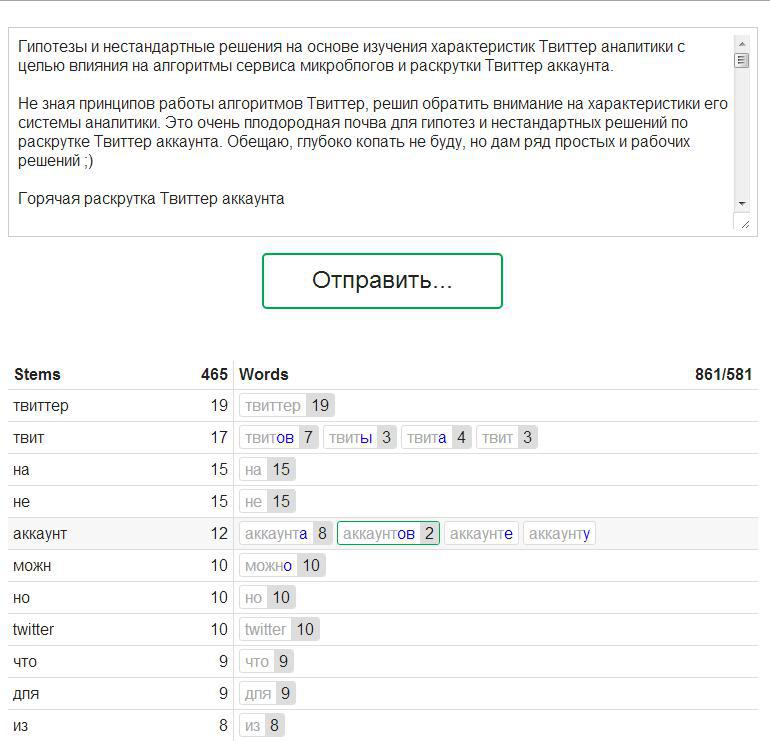
Скопировав PHP-скрипт на локальный сервер или сервер хостинг провайдера, вы получаете простой и удобный сервис анализа текстов.
Результат работы «Stemmer» — таблица, состоящая из двух частей: Stems (основы слов) и Words (словоформы).
В заголовке таблицы для Stems отображено количество словоформ, а для Word — количество всех и уникальных слов.
В каждой строке таблицы отображаются основа и её словоформы. При этом для основы отображено общее количество словоформ, а для каждой словоформы — количество её упоминаний в тексте.
Примечание: если количество равно единице (1) оно не отображается.
На данный момент PHP-скрипт «Stemmer» можно
купить за символическую сумму — 10 рублей и более.
И так, имея под рукой Стеммер Портера, нахождение основы слова не займёт у вас много времени и ресурсов. Следовательно, вы можете решать ряд смежных задач поиска и аналитики текстов. В качестве наглядного примера, предложен PHP-скрипт «Stemmer». Имея символическую цену, он станет полезным приобретением для копирайтеров, сеошников, др.
Какой максимальный объем обрабатываемого текста? Можно ли доработать так чтобы считал не отдельные слова, а словосочетания из 2х и 3х слов?
В самом скрипте ограничения на объём текста нет, но есть ограничение по ресурсам сервера: объём памети, лимит времени выполнения скрипта и прочее. Увы, но Стеммер Портера тоже чего-то потребляет, плюс обработка самого результата.
Что же до слово-сочетаний, то это реализуемо; подумаю, может и сделаю что-то такое.
Спасибо за код!
Поставил на сервак. Английский текст обрабатывает хорошо, а на русском не дает результата.
В чем может быть косяк?
Скрин https://yadi.sk/i/kZn9o9BQ32jd6Q
Самый вероятный вариант — при заливке скриптов на сервер у файлов слетела UTF кодировка. Т.е. нужно будет перекодировать в UTF-8.
Первое, что советую глянуть — в какой кодировке браузер отображает страницу.
Возможно и то, что сервер не поддерживает функции для работы с многобайтными строками, вида mb_***.
Здесь надо глянуть логии сервера, он может запретить вывод ошибок, даже не смотря на то, что в скрипте задан вывод всех ошибок и предупреждений.
Вспомнил ещё один момент. Попробуй заменить строку:
$in = preg_match_all("'\w{2,}'u", $in, $m) ? $m[0] : array();
на следующую:
$in = preg_match_all("'[a-zа-яё]{2,}'u", $in, $m) ? $m[0] : array();
Не все сервера нормально поддерживают спецсимвол \w, зачастую он не включает кикрилицу.